Note: This text was copied from the read me of our edition of Muḥammad Kurd ʿAlī’s journal al-Muqtabas and is in urgent need of updating.
In the context of the current onslaught cultural artifacts in the Middle East face from the iconoclasts of the Islamic State, from the institutional neglect of states and elites, and from poverty and war, digital preservation efforts promise some relief as well as potential counter narratives. They might also be the only resolve for future education and rebuilding efforts once the wars in Syria, Iraq or Yemen come to an end.
Early Arabic periodicals, such as Butrus al-Bustānī’s al-Jinān (Beirut, 1876–86), Yaʿqūb Ṣarrūf, Fāris Nimr, and Shāhīn Makāriyūs’ al-Muqtaṭaf (Beirut and Cairo, 1876–1952), Muḥammad Kurd ʿAlī’s al-Muqtabas (Cairo and Damascus, 1906–16) or Rashīd Riḍā’s al-Manār (Cairo, 1898–1941) are at the core of the Arabic renaissance (al-nahḍa), Arab nationalism, and the Islamic reform movement. Due to the state of Arabic OCR and the particular difficulties of low-quality fonts, inks, and paper employed at the turn of the twentieth century, they can only be digitised by human transcription. Yet despite of their cultural significance and unlike for valuable manuscripts and high-brow literature, funds for transcribing the tens to hundreds of thousands of pages of an average mundane periodical are simply not available. Consequently, we still have not a single digital scholarly edition of any of these journals. But some of the best-funded scanning projects, such as Hathitrust, produced digital imagery of numerous Arabic periodicals, while gray online-libraries of Arabic literature, namely shamela.ws, provide access to a vast body of Arabic texts including transcriptions of unknown provenance, editorial principals, and quality for some of the mentioned periodicals. In addition, these gray “editions” lack information linking the digital representation to material originals, namely bibliographic meta-data and page breaks, which makes them almost impossible to employ for scholarly research.
With the GitHub-hosted TEI edition of Majallat al-Muqtabas we want to show that through re-purposing available and well-established open software and by bridging the gap between immensely popular, but non-academic (and, at least under US copyright laws, occasionally illegal) online libraries of volunteers and academic scanning efforts as well as editorial expertise, one can produce scholarly editions that remedy the short-comings of either world with very little funding: We use digital texts from shamela.ws, transform them into TEI XML, add light structural mark-up for articles, sections, authors, and bibliographic metadata, and link them to facsimiles provided through the British Library’s “Endangered Archives Programme” and HathiTrust (in the process of which we also make first corrections to the transcription). The digital edition (TEI XML and a basic web display) is then hosted as a GitHub repository with a CC BY-SA 4.0 licence.
By linking images to the digital text, every reader can validate the quality of the transcription against the original, thus overcoming the greatest limitation of crowd-sourced or gray transcriptions and the main source of disciplinary contempt among historians and scholars of the Middle East. Improvements of the transcription and mark-up can be crowd-sourced with clear attribution of authorship and version control using .git and GitHub’s core functionality. Editions will be referencable down to the word level for scholarly citations, annotation layers, as well as web-applications through a documented URI scheme.1 The web-display is implemented through a customised adaptation of the TEI Boilerplate XSLT stylesheets; it can be downloaded, distributed and run locally without any internet connection—a necessity for societies outside the global North. Finally, by sharing all our code (mostly XSLT) in addition to the XML files, we hope to facilitate similar projects and digital editions of further periodicals, namely Rashīd Riḍā’s al-Manār.
1. Scope and deliverables of the project
The purpose and scope of the project is to provide an open, collaborative, referencable, and scholarly digital edition of Muḥammad Kurd ʿAlī’s journal al-Muqtabas, which includes the full text, semantic mark-up, bibliographic metadata, and digital imagery. All files but the digital facsimiles are hosted on GitHub.
All deliverables and milestones will be covered in more detail in the following sections.
1.1 Deliverables
- Current deliverables:
- Full text of 96 issues (c. 7000 pages) with semantic mark-up as TEI P5 XML with its own schema.
- The text of digital edition links to open-access digital facsimiles if available (see below).
- A webview, based on TEI Boilerplate, shows digital text and images side by side. It provides an automatically generated table of content and links to the bibliographic metadata of every article.
- Bibliographic metadata for every article in Majallat al-Muqtabas is provided as individual MODS and BibTeX files in the sub-folder
metadata. The metadata includes a URL pointing to the webview of this item and the webview includes a link to the metadata files for every article.- To ease browsing the journal, we have set up the public Zotero group Digital Muqtabas. This group is updated by means of the MODS XML files.
- Possible / planned deliverables
- Scans of issues not currently available in open-access repositories, namely of vol. 9, which we hold at Orient-Institut Beirut.
The project will open avenues for re-purposing code for similar projects, i.e. for transforming full-text transcriptions from some HTML or XML source, such as al-Maktaba al-Shamela, into TEI P5 XML, linking them to digital imagery from other open repositories, such as EAP and HathiTrust, and generating a web display by, for instance, adapting the code base of TEI Boilerplate.
The most likely candidates for such follow-up projects are
- Muḥammad Rashīd Riḍā’s journal al-Manār. A stub is already available on GitHub
- full text from shamela: 8605 views
- imagery from hathitrust,imagery / PDFs from the Internet Archive, which are linked from al-Maktaba al-Waqfiyya
- ʿAbd al-Qādir bin Muḥammad Salīm al-Kaylānī al-Iskandarānī’s majallat al-ḥaqāʾiq (al-dimashqiyya), 1910. Using the code and experiences from Digital Muqtabas, Digital Ḥaqāʾiq was created within only a single day’s work.
- full text from shamela: 5134 views.
- imagery of vol. 1 (1910) from hathitrust, vol. 2 and 3 are available at AUB.
- ʿAbdallah al-Nadīm’s majallat al-ustādh, Cairo, 24 Aug 1892
- full text from shamela: 11337 views.
1.2 Milestones
- Design a basic TEI schema; done
- Import everything from shamela and convert it to TEI XML; done
- Improve TEI mark-up: The following steps are independent of each other, need to be done on the issue / file level, and can be distributed across different editors.
- Bibliographic metadata: volume, issue, page range
- Basic structural mark-up: sections, articles, heads, authors
- Page breaks and links to facsimiles
- Adapt TEI Boilerplate to the needs of Arabic periodicals; done
- Write XSLT to extract bibliographic metadata for every article in al-Muqtabas
- Basic: BibTeX; done
- Advanced: MODS; done
- Presentations to solicit feedback
- Leipzig, Germany, December 2015: DH Workshop Persian and Arabic
- Cologne, Germany, March 2016: DiXiT Convention 2
- Cairo, Egypt, April 2016: Webinar at AUC library
- Beirut, Lebanon, May 2016: Conference “Books in Motion”
- Krakow, Poland, August 2016: DH2016 cancelled (due to parental leave)
1.3 Timeline / scheduled releases
There is no proper release schedule yet but I conceive of version 1.0 as the first complete edition.
- version 0.1 shall be the first “official” release. It is scheduled for May/June 2016 and will include
- TEI files of all at least one volume of al-Muqtabas (i.e. 12 issues / files) with structural mark-up of mastheads, sections, articles, and with page breaks linked to the facsimiles; for no other reason but interes in their content, we have started work on vol. 5 and 6, which are therefore the most likely release candidates;
- MODS / BibTeX files for all issues, sections, and articles;
- XSLT stylesheets for all necessary initial and periodic conversions;
- XSLT, JS, and CSS for a webview.
- versions 0.1 - 0.x: each completed volume of 11 to 12 issues / TEI files will warant an incremental release.
- version 1.0 shall include
- TEI files of all 96 issues of al-Muqtabas with structural mark-up of mastheads, sections, articles, and with page breaks linked to the facsimiles;
- all the components of version 0.1
2. Input:
2.1 Digital imagery
Image files are available from the al-Aqṣā Mosque’s library in Jerusalem through the British Library’s “Endangered Archives Project” (vols. 2-7), HathiTrust (vols. 1-6, 8), and Institut du Monde Arabe. Due to its open access licence, preference is given to facsimiles from EAP.
2.1.1 EAP119
- links to volumes:
- access:
- the journal is in the public domain and the images can be freely accessed without restrictions. EAP does not provide a download button.
- Terms of access for material provided by the British Library can be found here
2.1.2 HathiTrust
- links to volumes
- access
- The journal is in the public domain in the US and can be freely accessed and downloaded
- Outside the US, access is restricted.
- Formal licence:
Public Domain or Public Domain in the United States, Google-digitized: In addition to the terms for works that are in the Public Domain or in the Public Domain in the United States above, the following statement applies: The digital images and OCR of this work were produced by Google, Inc. (indicated by a watermark on each page in the PageTurner). Google requests that the images and OCR not be re-hosted, redistributed or used commercially. The images are provided for educational, scholarly, non-commercial purposes.
Note: There are no restrictions on use of text transcribed from the images, or paraphrased or translated using the images.
2.1.3 arshīf al-majallāt al-adabiyya wa-l-thaqafiyya al-ʿarabiyya (archive.sakhrit.co)
Recently, a colleague pointed me to another gray online library of Arabic material—one that was entirely dedicated to cultural and literary journals: arshīf al-majallāt al-adabiyya wa-l-thaqafiyya al-ʿarabiyya (archive.sakhrit.co). I have posted a review of the website on my blog.
Among their collection is also the journal al-Muqtabas and they provide:
- Partially watermarked digital imagery
- Functional tables of content for each issue, including author, title, page number
- Some bibliographic metadata on the issue level
After some assessment it turned out that at least volumes 4 and 5, were indeed rendered from a modern digital text, namely shamela’s transcription!
{kind=link}
{kind=link}
Therefore archive.sakhrit is even more problematic than shamela in terms of scholarly use. The user is always aware of reading a derivative with an unknown relation to an assumed original while accessing a text from shamela. At archive.sakhrit, on the other hand, the user is deceived by a seemingly faithful representation of a fake original.
In the future we will link to the archive.sakhrit’s digital facsimiles for those volumes that have been scanned from the original. These are:
- Vol. 1: links to this volume are of particular importance as no scans are availble from EAP and those from HathiTrust remain unaccessible to the majority of potential users.
2.1.3 other sources
- Institut du Monde Arabe: bibliothèque numérique.
2.2 Full text
Somebody took the pains to create fully searchable text files and uploaded everything to al-Maktaba al-Shamela and WikiSource.
2.2.1 al-Maktaba al-Shāmila
The digital text of al-Muqtabas on shamela.ws comprises all 96 issues totalling some 1.9 million words. It was transcribed from either digital facsimiles or original copies by anonymous transcribers following undocumented editing principles. Comparison with the original print edition allows us to discern common transcription errors, such as missing lines or characters, which indicate that shamela.ws’s text was indeed transcribed by humans without quality control through double-keying usually required for scholarly transcriptions (see no. 4(2), p.82, no. 4(3), p.158, and no. 6(12), pp.799–800 for examples). The comparison also reveals that shamela.ws principally omitted mastheads, all words in Latin script (mainly technical terms and proper nouns) and all footnotes.
The transcription has a number of substantial and unmarked gaps, ranging from a single paragraph to multiple pages (see no. 5(7), pp. 463–466 and no. 5(12), pp. 761–765 for examples). Some of these could be due to pages missing from the original from which the transcribers worked or page-turning errors. Others remain enigmatic and might have been driven by editorial choices. Someone copy edited the transcription, adding punctuation marks absent from the original and hamzas not commonly found in the original and thus, inter alia, differentiating between inna and anna. Some geographic names were normalised.
In terms of structural mark-up, shamela.ws did not provide but an ecclectic selection of top-level headers. Bibliographic metadata is all but nonexisting, since shamela.ws supplied faulty Gregorian publication dates and its own consecutive issue count that ignores the original collation into volumes.
- Transcribers, editors: Apparently, they have been typed and copy-edited by unnamed humans.
- Features edition: paragraphs, page breaks, some headlines.
- Features interface:
- all issues can be browsed for headlines and searched
- all pages can be individually adressed in the browser: http://shamela.ws/browse.php/book-26523#page-2290
2.2.2 WikiSource
Sombody uploaded the text from shamela to WikiSource. Unfortunately it is impossible to browse the entire journal. Instead one has to adress each individual and consecutively numbered issue, e.g. Vol. 4, No. 1 is listed as No. 37
3. Deliverable: TEI edition
The main challenge is to combine the full text and the images in a TEI edition. As al-maktabat al-shāmila did not reproduce page breaks true to the print edition, every single one of the more than 6000 page breaks must be added manually and linked to the digital image of the page.
3.1 General design
The edition is conceived of as a corpus of TEI files that are grouped by means of XInclude. This way, volumes can be constructed as single TEI files containing a <group/> of TEI files and a volume specific <front/> and <back/>
Detailled description and notes on the mark-up are kept in a separate file (documentation_tei-markup.md).
3.2 Quality control
A simple way of controlling the quality of the basic structural mark-up would be to cross check any automatically generated table of content or index against the published tables of content at the end of each volume and against the index of al-Muqtabas published by Riyāḍ ʿAbd al-Ḥamīd Murād in 1977.
3.3 To do
- Mark-up: The basic structural mark-up of individual issues is far from complete. All features encoded in HTML by shamela.ws have been translated into TEI XML, but these are limited to the main article / section headers. What needs to be done is:
- splitting articles into sections and sections into individual articles
- mark-up of authors with
<byline>
- Text-image linking: while the links to the facsimiles can be automatically generated for each issue, establishing page breaks (
<pb>) must be done manually for all 6.000+ of them
4. Deliverable: A web display adapting TEI Boilerplate
To allow a quick review of the mark-up and read the journal’s content, I decided to customise TEI Boilerplate for a first display of the TEI files in the browser without need for pre-processed HTML and to host this heavily customised boilerplate view as another GitHub repository to be re-used.
The webview provides a parallel display of either online or local facsimiles and the text of al-Muqtabas. It includes a fully functional table of contents, stable links to all section and article heads, and links to bibliographic metadata for every article. For a first impression see al-Muqtabas 6(2).
](/assets/images/boilerplate_muqtabas-1.jpg)
 with expanded table of content](/assets/images/boilerplate_muqtabas-2.jpg)
A detailed description of the web display is available here.
User will, of course, want to search the edition for specific terms and will immediately recognise the lack of a dedicated search field in the webview. But behold, individual issues can be searched through the built-in search function in browsers; just hit ctrl+f (windows) or cmd+f (macintosh) to search individual periodical issues for literal strings. To search across the entire periodical, there are three instantly available options:
- the GitHub repository, which allows for browsing and searching and displays search results in context.
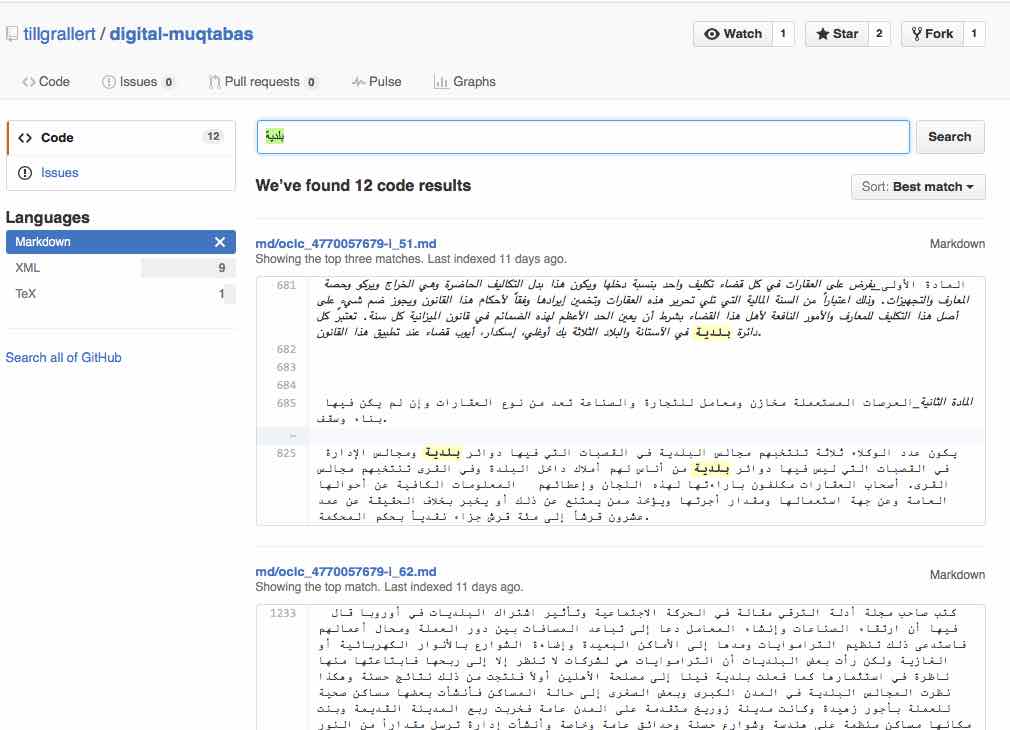
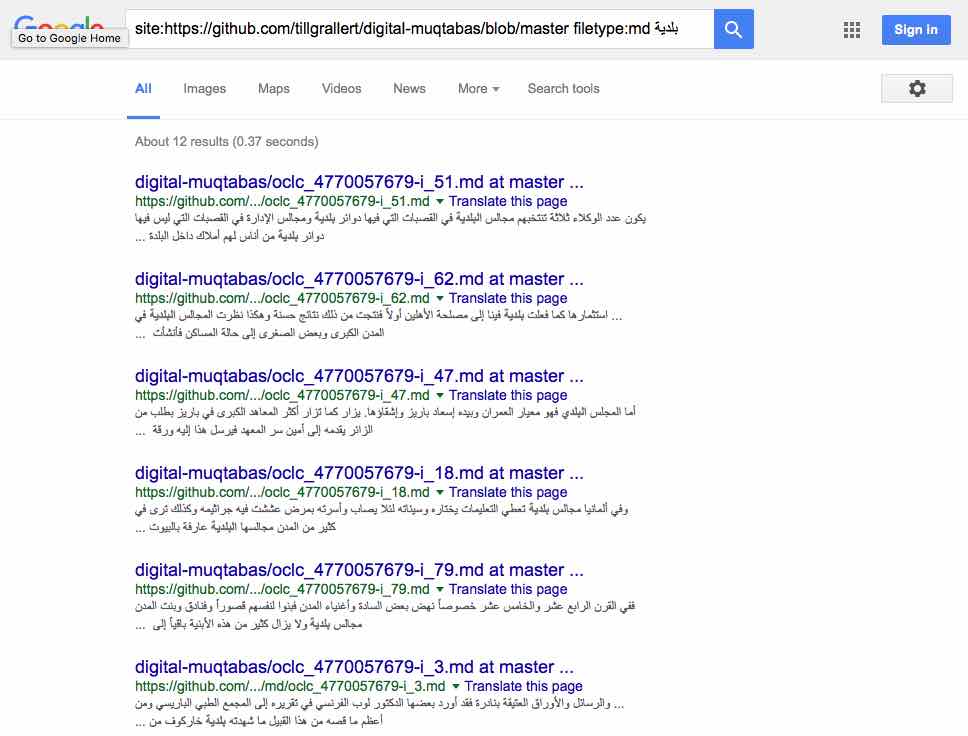
- Google’s web search provides a
site:operator that can be extensively manipulated:site:https://github.com/openarabicpe/journal_al-muqtabas/blob/master search stringwill search all files in the Digital Muqtabas repository.- add
filetype:xmlto search only XML files. Other options would befiletype:mdfor plain text markdown files,filetype.bibfor BibTeX files etc.
- a public Zotero group comprising bibliographic metadata for all articles and sections, including author names, titles, publication dates, volume and issue numbers etc., including links to the webview.
5. Deliverable: Bibliographic metadata / index
Bibliographic metadata for every article in Majallat al-Muqtabas is provided in two formats: BibTeX and MODS in the sub-folder metadata. The metadata includes a URL pointing to the webview of this item and the webview, in turn, includes links to the metadata files for every article.
5.1 BibTeX
BibTeX is a plain text format which has been around for more than 30 years and which is widely supported by reference managers. Thus it seems to be a safe bet to preserve and exchange minimal bibliographic data. The repository currently contains two XSLT stylesheets to automatically generate BibTeX files from the TEI source:
Tei2BibTex-articles.xsl: generates one BibTeX file for each article and section of a periodical issue.Tei2BibTex-issues.xsl: generates one BibTeX file per periodical issue, comprising entries for every article and section.
There are, however, a number of problems with the format:
- The format and thus the tools implementing it aren’t really strict.
- The format description is fairly short and since development of BibTeX stalled between 1988 and 2010, it is most definitely not the most current or detailed when it comes to bibliographic metadata descriptions.2
- Only basic information can be included:
- information on publication dates is commonly limited to year and month only
- periodicals are not perceived as having different editions or print-runs
- non-Gregorian calendars cannot be added.
5.2 MODS (Metadata Object Description Schema)
The MODS standard is expressed in XML and maintained by the Network Development and MARC Standards Office of the Library of Congress with input from users. Compared to BibTeX MODS has he advantage of being properly standardised, human and machine readable, and much better suited to include all the needed bibliographic information.
The repository currently contains two XSLT stylesheets to automatically generate MODS XML files from the TEI source:
Tei2Mods-articles.xsl: generates one MODS file for each article and section of a periodical issue.Tei2Mods-issues.xsl: generates one MODS file per periodical issue, comprising entries for every article and section.
MODS also serves as the intermediary format for the free bibutils suite of conversions between bibliographic metadata formats (including BibTeX) which is under constant development and released under a GNU/GPL (General Public License). Tei2Mods-issues.xsl and bibutils provide a means to automatically generate a large number of bibliographic formats to suit the reference manager one is working with; e.g.:
- to generate EndNote (refer-format) one only needs the following terminal command:
$xml2end MODS.xml > output_file.end - to generate BibTex:
$xml2bib MODS.xml > output_file.bib
5.3 Index by means of a Zotero group
As the webview or reading edition is implemented on the issue level and as we have currently no plans to implement and host a database on the backend, Digital Muqtabas needed a way to navigate and browse all articles, authors etc. To this end, we have set up the public Zotero group “Digital Muqtabas” (bibliographic metadata). It can be updated by means of the MODS or BibTeX files. Updating from MODS is the preferred method since it is the more expressive format.
Zotero groups are great way to share bibliographic metadata. Hosted by the Roy Rosenzweig Center for History and Media, they allow for public access to structured bibliographic metadata through a web interface. Of course they also integrate with the free and open-source reference manager Zotero. All one needs is a free Zotero account and either the Zotero plug-in for the Firefox and Chrome browsers or the Zotero standalone version for Mac OSX and Linux. One can then join the group and sync all data to the local installation of Zotero, which means that, similar to the webview and all other components of this edition, bibliographic metadata can be browsed and searched through a graphical user interface without a continuous internet connection.
-
Currently we provide stable URLs down to the paragraph level. For more details see the documentation of the mark-up ↩
-
Wikipedia has a better description than the official website. ↩