The work on digital scholarly editions (DSE) of late Ottoman Arabic periodicals continued within the framework of OpenArabicPE (see annual report 2017). I added a number of periodicals to the existing editions of Muḥammad Kurd ʿAlī’s al-Muqtabas (Damascus and Cairo, 1906–18) and ʿAbd al-Qādir al-Iskandarānī’s al-Ḥaqāʾiq (Damascus, 1910–12) following the principles and workflows established over the last years. These are: Anastās Mārī al-Karmalī’s monthly journal Lughat al-ʿArab (Baghdad, 1911–14), Anṭūn al-Jumayyil’s monthly journal al-Zuhūr (Cairo, 1910–1913) and Abd Allāh Nadīm al-Idrīsī’s weekly journal al-Ustādh (Cairo, 1892–1893). The ability to quickly add and release a number of periodicals with full text and digital facsimiles was helped by the anonymous transcribers at al-Maktaba al-Shāmila, who reproduced the page breaks as found in the printed originals that allow us to quickly link the text to the facsimile. This is very different from both al-Muqtabas and al-Ḥaqāʾiq for which we had to add each of the 8000+ page breaks manually. Finally, I worked on a facsimile edition with transcriptions of article titles and bylines of Jirjī Niqūlā Bāz’s al-Ḥasnāʾ (Beirut, 1909–11).
In the last report, I mentioned the importance of authorship attribution for the vast majority of anonymous articles if one wants to analyse the (social) network of authors and texts that form the ideosphere of the Arabic press in the Eastern Mediterranean. The, often implicit and accepted, hypothesis is that a periodical’s editors authored all articles for which they did not provide a meaningful byline. There are two issues with this hypothesis: first, it remains untested and, second, we do not even know all the editors working at any given paper. We commonly have only the names of a paper’s proprietor and, sometimes, a responsible editor. In 2018, I engaged in first stylometric analyses for authorship attribution. Stylometry, in this context, basically means a computational comparison of the frequency of most-frequent words (MFW) across all texts within our corpus with a sufficient length using the “stylo” package in R, developed by Maciej Eder et al.. While stylometry is well-established for authorship attribution. My efforts represent the first application of stylometry to Arabic texts. In addition, the main challenge to the stylometric analysis of periodical articles is the minimal required length for statistical significant authorship attribution, which has been shown to lay around 5000 words for European languages. The figure is the result of all articles above 5000 words in al-Muqtabas, al-Ḥaqāʾiq and Lughat al-ʿArab using a bootstrap consensus network for 100–1000 MFWs in increments of 100.
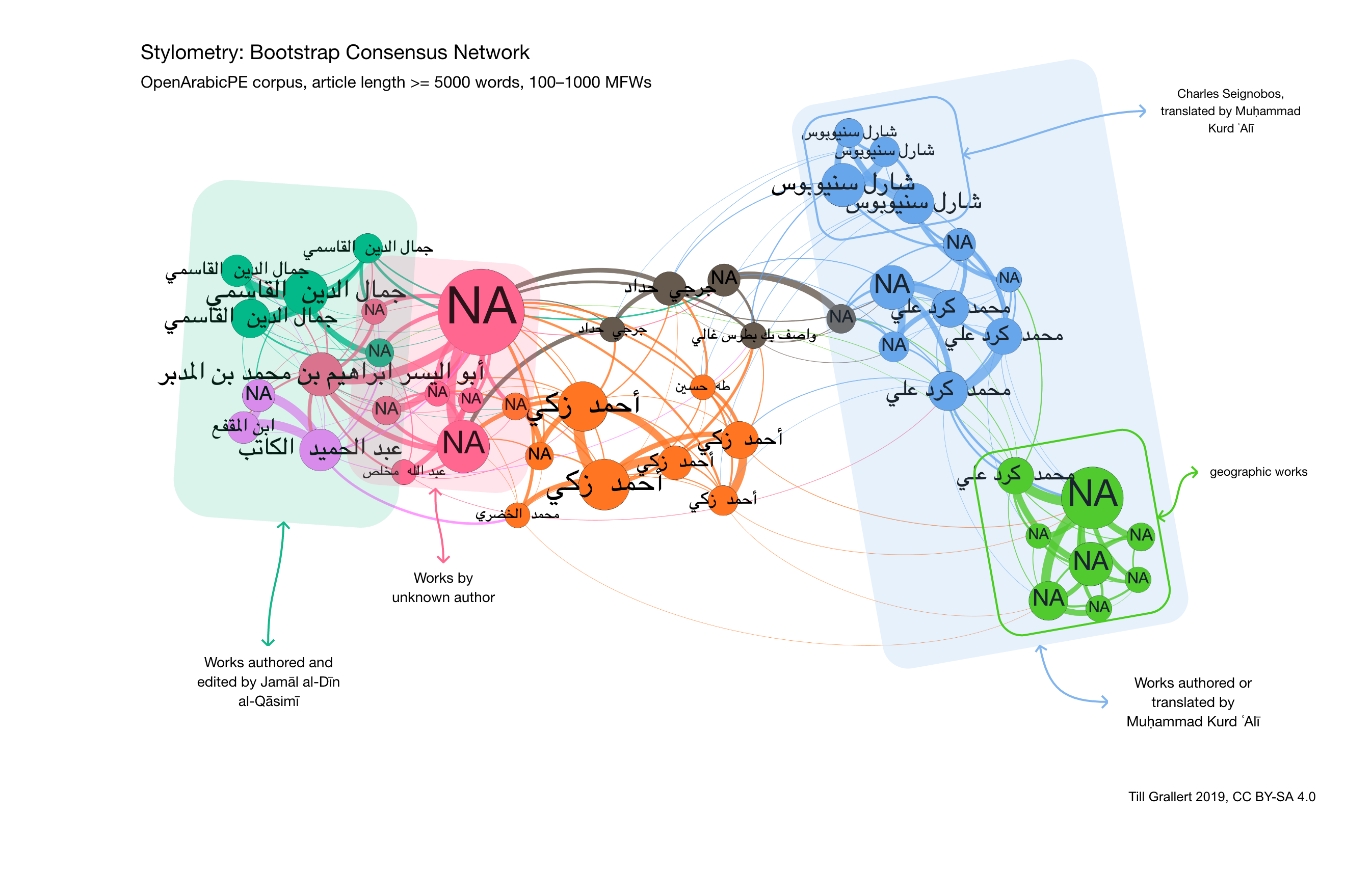
The network plot shows that the algorithm indeed works for Arabic texts: text with known authors cluster together by author, confirming an authorship signal. On the right side we also see a translator’s signal in the blue cluster: Kurd ʿAlī was the translator of Charles Seignobos’ works into Arabic. The plot shows only limited stylistic overlap between authors and we can assume with a high degree of confidence that the cluster of anonymous articles in light green on the bottom right was authored by Kurd ʿAlī. This would confirm the authorship hypothesis for al-Muqtabas, the origin of all but one article in this plot. However, this plot shows a second cluster of unattributed articles in red that are stylistically clearly distinct from Kurd ʿAlī’s writings. This in turn falsifies the hypothesis and necessitated further approaches to the material.
A first peer-reviewed article, including first results of network analysis and stylometry, will be published in a special issue of “Geschichte & Gesellschaft” on digital history in 2020.